Machine Learning
Machine Learning (ML) é um campo da inteligência artificial (IA) que se concentra no desenvolvimento de algoritmos e modelos que permitem que os computadores aprendam a partir de dados e façam previsões ou decisões sem serem explicitamente programados para realizar essas tarefas. Em vez de seguir instruções específicas, os sistemas de ML utilizam padrões e inferências dos dados fornecidos para melhorar seu desempenho ao longo do tempo.
Por que isso é importante: É crucial para abordar problemas complexos em diversas áreas, como previsão de séries temporais, reconhecimento de padrões e tomada de decisões automatizadas. Além disso, ajuda a distinguir Machine Learning de outras áreas da computação e da inteligência artificial, fornecendo um contexto para as técnicas, desafios e aplicações, especialmente no desenvolvimento de modelos preditivos usando redes neurais recorrentes e na aplicação da metodologia CRISP-DM.
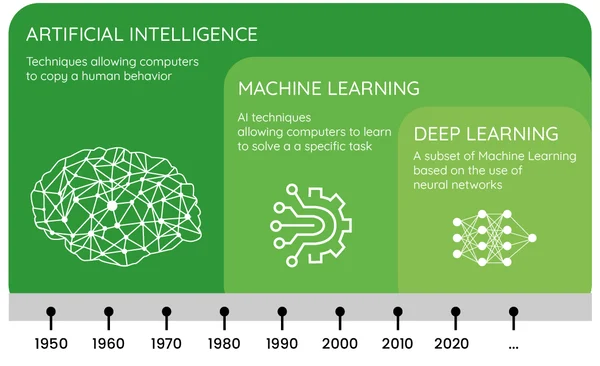
A Inteligência Artificial (IA) é o campo mais amplo e abrangente entre os três. Ela se refere à criação de sistemas computacionais capazes de realizar tarefas que normalmente requerem inteligência humana. Isso inclui áreas como raciocínio, resolução de problemas, planejamento, aprendizado, percepção e processamento de linguagem natural. A IA engloba uma variedade de abordagens, desde sistemas baseados em regras até métodos de aprendizado de máquina mais avançados.
Machine Learning (ML) é um subconjunto da IA que se concentra em algoritmos e modelos estatísticos que permitem aos sistemas melhorar seu desempenho em uma tarefa específica através da experiência, sem serem explicitamente programados para cada situação. ML utiliza dados para treinar modelos que podem fazer previsões ou tomar decisões. Existem várias abordagens em ML, incluindo aprendizado supervisionado, não supervisionado e por reforço.
Deep Learning, por sua vez, é um subconjunto especializado do Machine Learning, inspirado na estrutura e função do cérebro humano, particularmente nas redes neurais. Ele utiliza redes neurais artificiais com múltiplas camadas (daí o termo "deep", ou profundo) para aprender representações hierárquicas dos dados. Deep Learning é particularmente eficaz em tarefas complexas como reconhecimento de imagem, processamento de linguagem natural e, relevante para nosso curso, análise de séries temporais através de redes neurais recorrentes.
A principal diferença entre ML e Deep Learning está na complexidade dos modelos e na quantidade de dados necessários. Enquanto técnicas tradicionais de ML podem funcionar bem com conjuntos de dados menores e muitas vezes requerem engenharia de features manual, o Deep Learning geralmente requer grandes quantidades de dados, mas pode automaticamente aprender características relevantes.
Tipos de Aprendizado
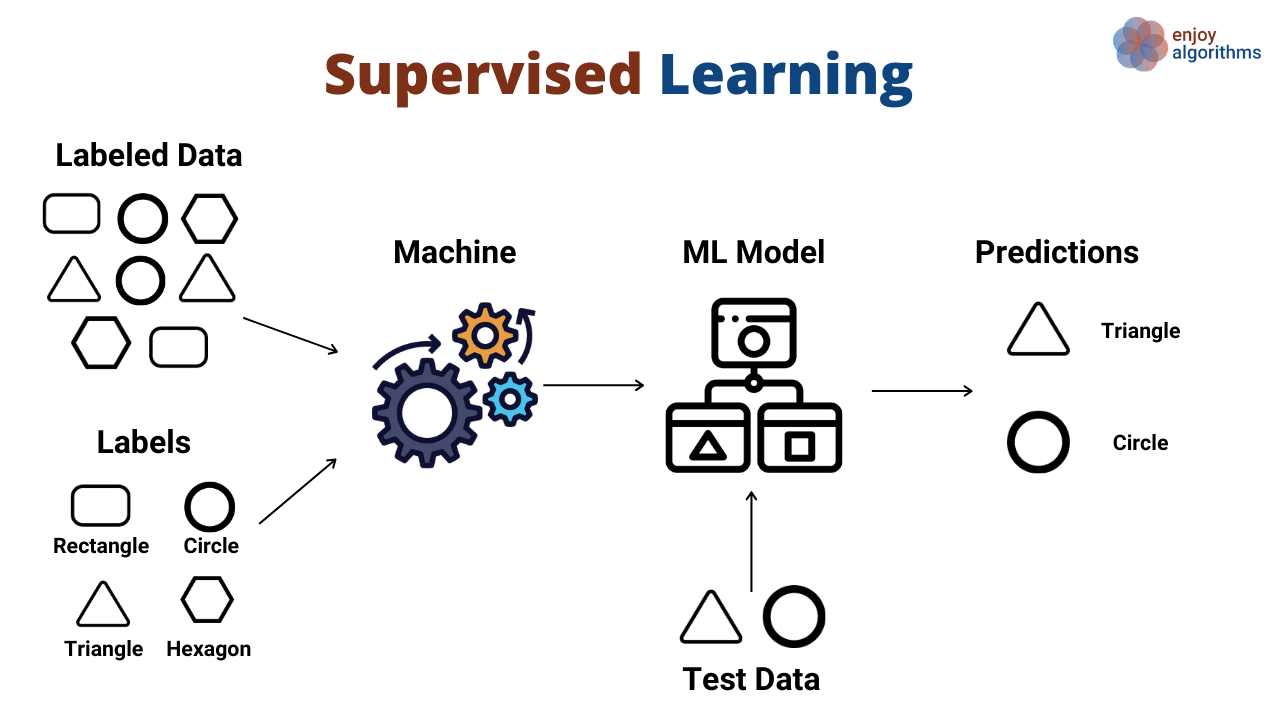
Aprendizado Supervisionado é o tipo mais comum de ML. Neste método, o algoritmo é treinado com um conjunto de dados rotulados, onde cada exemplo consiste em pares de entrada-saída. O objetivo é aprender uma função que mapeie corretamente as entradas para as saídas correspondentes. Durante o treinamento, o modelo faz previsões e ajusta seus parâmetros com base no erro entre suas previsões e os rótulos reais. Exemplos típicos incluem problemas de classificação (como identificar spam em e-mails) e regressão (como prever preços de imóveis). No contexto de séries temporais, o aprendizado supervisionado pode ser usado para prever valores futuros com base em dados históricos rotulados.
Aprendizado Não Supervisionado trabalha com dados não rotulados. O objetivo aqui é descobrir padrões ou estruturas ocultas nos dados sem orientação explícita. Estes algoritmos tentam agrupar, reduzir dimensionalidade ou encontrar associações nos dados. Técnicas comuns incluem clustering (como agrupar clientes com comportamentos similares) e redução de dimensionalidade (como PCA para visualização de dados de alta dimensão). Em séries temporais, o aprendizado não supervisionado pode ser útil para detectar anomalias ou identificar padrões sazonais em dados não rotulados.

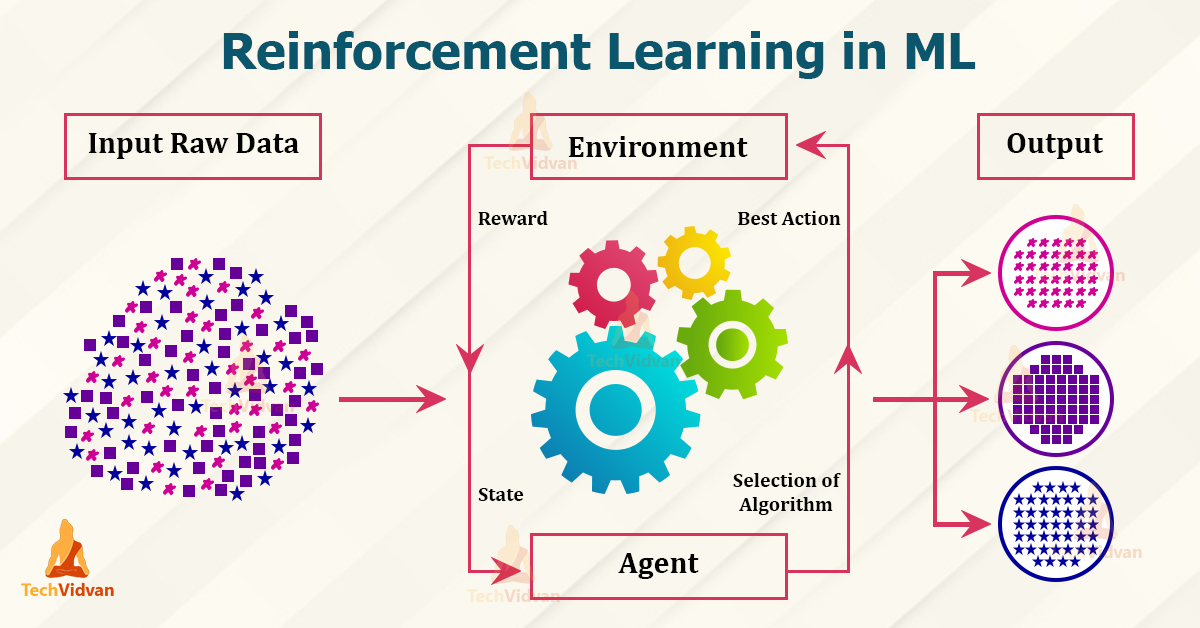
Aprendizado por Reforço é um paradigma onde um agente aprende a tomar decisões interagindo com um ambiente. O agente recebe recompensas ou penalidades baseadas em suas ações, e seu objetivo é maximizar a recompensa cumulativa ao longo do tempo. Diferente do aprendizado supervisionado, não há rótulos explícitos, mas sim um sistema de recompensas. Este tipo de aprendizado é particularmente útil em cenários de tomada de decisão sequencial, como jogos, robótica ou otimização de sistemas. Embora menos comum em análise de séries temporais tradicionais, o aprendizado por reforço pode ser aplicado em cenários de previsão e tomada de decisão em tempo real baseados em dados de séries temporais.
No contexto nosso contexto, focaremos principalmente no aprendizado supervisionado, pois estaremos trabalhando com dados históricos rotulados para prever valores futuros. No entanto, técnicas de aprendizado não supervisionado podem ser úteis na fase de preparação e exploração dos dados.
Pessoal desse ponto em diante, vamos iniciar nossa revisão dos conceitos aplicando eles em alguns projetos. A metodologia CRISP-DM será nossa guia para a construção dos modelos e avaliação de desempenho. Além do material de autoestudo, recomendo fortemente a leitura do artigo do Fayyad et al. - From Data Mining to Knowledge Discovery in Databases, que é um dos primeiros artigos a descrever o processo de mineração de dados, que fundamenta diversas técncias que vamos utilizar.