Instrução de Orientação
Preparação dos Entregáveis
1. Objetivos
- Orientação sobre os entregáveis da Sprint 2.
- Manipulação de arquivos com Python.
- Utilizando bancos de dados documentais com Python.
2. Slides do Encontro
3. Material de Autoestudo
Esse material NÃO substitui de forma alguma o uso da Adalove. Você DEVE entrar na Adalove com frequência e REGISTRAR O SEU PROGRESSO. Entendeu? Ainda não? Pera aí que vou desenhar:
- 📘 Autoestudos Obrigatórios
- 📔 Autoestudos Opcionais
- 📓 Autoestudos Adicionais
Python TinyDB: base de dados em arquivos JSON
TinyDB - Getting Started
Como usar JSON em PYTHON - Arquivos e Strings

Reading and Writing Files in Python (Guide)
File Handling in Python
SQL vs. NoSQL Explained (in 4 Minutes)
Which Is Better? SQL vs NoSQL
Live de Python #8 - CRUD com SQLite3
DATA SCIENCE SKILLS: Gentle Introduction to sqlite3. Python, SQLite and Databases
4. Material de Aula
Chegamos agora ao momento de armazenar nossos dados 🎲🎲!! Um conceito bastante importante, quando nosso programa é executado, os valores manipulados por ele estão na memória RAM do sistema (nosso computador, servidor o que for!). Quando o programa é encerrado, os valores são perdidos. Para que isso não aconteça, precisamos armazenar esses valores em algum lugar. E é aí que entra a persistencia!.
O que é a persistência? É a capacidade de um sistema de armazenar dados de forma que eles possam ser recuperados posteriormente. E é isso que vamos aprender a fazer nesse encontro. Vamos aprender a armazenar nossos dados em arquivos e em bancos de dados.
Tudo que vamos desenvolver estará disponível no diretório orientacao-5. Na dúvida sobre a estrutura básica dos arquivos ou como criar um ambiente virtual? Verificar nosso encontro anterior desta semana!!
4.1. Arquivos
A primeira forma de armazenarmos os dados é em arquivos. E para isso, vamos utilizar a biblioteca padrão do Python para manipulação de arquivos. Vamos aprender a abrir, ler, escrever e fechar arquivos. Além disso, vamos aprender a manipular arquivos JSON, que é um formato de arquivo bastante utilizado para armazenar dados.
Mas Murilão por que vamos utilizar arquivos para armazenar os dados? Guardar os dados em arquivos é uma prática comum e bastante útil. Por exemplo, imagine que você está desenvolvendo um jogo e quer salvar o progresso do jogador. Você pode salvar esses dados em um arquivo. Ou então, imagine que você está desenvolvendo um sistema de cadastro de clientes. Você pode salvar os dados dos clientes em um arquivo.
Arquivos de configuração ou mesmo para realizar o armazenamento de arquivos de texto são uma prática comum. No entanto, é importante ressaltar que essa prática não é recomendada para grandes volumes de dados. Para isso, existem os bancos de dados.
A manipulação de arquivos pode ser realizada utilizando bibliotecas built-in do Python. Vamos trabalhar com o arquivo arquivos.py. Para executar ele vamos rodar o comando: python3 src/arquivos.py.
# arquivos.py
import random
def escrever_arquivo(nome_arquivo, texto):
with open(nome_arquivo, 'w') as arquivo:
arquivo.write(texto)
def ler_arquivo(nome_arquivo):
with open(nome_arquivo, 'r') as arquivo:
return arquivo.read()
def gerar_numero():
return random.randint(0, 100)
def gerar_lista_numeros(tamanho):
return [gerar_numero() for _ in range(tamanho)]
def escrever_lista_arquivo(nome_arquivo, lista):
texto = '\n'.join(str(numero) for numero in lista)
escrever_arquivo(nome_arquivo, texto)
def ler_lista_arquivo(nome_arquivo):
texto = ler_arquivo(nome_arquivo)
return [int(numero) for numero in texto.split('\n') if numero]
def main():
lista = gerar_lista_numeros(10)
print(lista)
escrever_lista_arquivo('numeros.txt', lista)
lista_lida = ler_lista_arquivo('numeros.txt')
print(lista_lida)
if __name__ == '__main__':
main()
Vamos avaliar este código por partes:
-
escrever_arquivo: Função para escrever o texto. Ela recebe o nome do arquivo e o texto a ser escrito. A funçãoopenabre o arquivo no modo de escrita ('w'). O arquivo é fechado automaticamente ao final do blocowith. Owithé uma forma de garantir que o arquivo será fechado, mesmo que ocorra algum erro durante a execução do bloco. O métodowriteescreve o texto no arquivo. -
ler_arquivo: Função para ler o texto. Ela recebe o nome do arquivo e retorna o texto lido. A funçãoopenabre o arquivo no modo de leitura ('r'). O arquivo é fechado automaticamente ao final do blocowith. O métodoreadlê o texto do arquivo, todo de um única vez. Para que o arquivo seja lido linha a linha, podemos utilizar o métodoreadline. -
gerar_numero: Função para gerar um número aleatório entre 0 e 100. -
gerar_lista_numeros: Função para gerar uma lista de números aleatórios. Ela recebe o tamanho da lista e retorna uma lista com números aleatórios. -
escrever_lista_arquivo: Função para escrever uma lista de números em um arquivo. Ela recebe o nome do arquivo e a lista de números. O métodojoinjunta os números da lista em uma única string, separando-os por quebra de linha. O texto é escrito no arquivo. -
ler_lista_arquivo: Função para ler uma lista de números de um arquivo. Ela recebe o nome do arquivo e retorna a lista de números. O texto é lido do arquivo e separado em uma lista de números.
Vale destacar que as funções acima foram todas escritas utilizando o recurso de list comprehension. Caso você não esteja familiarizado com esse recurso, sugiro que dê uma olhada no material de autoestudo. Outra recomendação é reescrever esse código fonte utilizando a notação padrão de listas.
Observação Importante: Repare que quando apenas o nome do arquivo é passado para a função
open, ele é aberto no mesmo diretório do arquivo que está sendo executado. Caso você queira abrir um arquivo em outro diretório, você deve passar o caminho completo do arquivo.
Mas Murilão, e se eu quiser abrir um arquivo em outro diretório? Você pode passar o caminho completo do arquivo. Por exemplo, se você quiser abrir o arquivo
numeros.txtque está no diretóriodados, você pode passar o caminho completo do arquivo:dados/numeros.txt.
Pessoal vocês viram que para manipular o conteúdo do arquivo, utilizamos a função open que é uma função built-in do Python. Ela nos permite abrir arquivos em diferentes modos. Os principais modos são:
'r': Abre o arquivo para leitura. O arquivo deve existir. Caso o arquivo não exista, um erro será lançado.'w': Abre o arquivo para escrita. Se o arquivo já existir, ele será apagado. Se o arquivo não existir, ele será criado.'a': Abre o arquivo para escrita. Se o arquivo já existir, o conteúdo será mantido e os novos dados serão adicionados ao final do arquivo. Se o arquivo não existir, ele será criado.
Além desses modos, existem outros modos que podem ser utilizados. Para mais informações, consulte a documentação oficial.
Pessoal outra observação importante é que o arquivo é fechado automaticamente ao final do bloco with. Isso é muito importante, pois garante que o arquivo será fechado, mesmo que ocorra algum erro durante a execução do bloco. Caso você não utilize o bloco with, é importante que você feche o arquivo manualmente utilizando o método close.
Mas Murilão, e se eu não fechar o arquivo? Se você não fechar o arquivo, ele continuará aberto e ocupando memória. Isso pode causar problemas, como por exemplo, o arquivo não ser acessível para outros programas. Além disso, se você tentar abrir muitos arquivos sem fechá-los, você pode atingir o limite de arquivos abertos pelo sistema operacional.
Mas Murilão, tenho que ler todo o conteúdo do arquivo de forma sequêncial? Não necessariamente. Você pode ler o conteúdo do arquivo de forma sequêncial, ou seja, lendo todo o conteúdo de uma vez, ou então, você pode ler o conteúdo do arquivo linha a linha. Para isso, você pode utilizar o método
readline.
Mas será que não existe uma forma mais interessante de armazenar os dados? Algo que facilite a leitura de um valor específico, como o que foi setado para uma configuração específica? Claro que existe! Podemos trabalhar com arquivos JSON.
4.2. Arquivos JSON
O JSON (JavaScript Object Notation) é um formato de arquivo bastante utilizado para armazenar dados. Ele é um formato de texto que é fácil de ler e escrever. Além disso, ele é fácil de ser interpretado e gerado por máquinas. O JSON é um formato de arquivo bastante utilizado para armazenar configurações, dados de usuários, dados de jogos, entre outros.
O JSON veio do JavaScript, mas é um formato de arquivo independente de linguagem. Isso significa que ele pode ser utilizado em qualquer linguagem de programação. No Python, o JSON é suportado pela biblioteca json, que é uma biblioteca built-in do Python. O JSON é um formado de arquivo bastante similar a um dicionário. Ele é composto por pares de chave e valor. As chaves são strings e os valores podem ser strings, números, objetos, arrays, booleanos ou nulos. Para saber mais sobre o JSON, consulte a documentação oficial.
Vamos trabalhar com o arquivo arquivos_json.py. Para executar ele vamos rodar o comando: python3 src/arquivos_json.py.
# arquivos_json.py
import json
def escrever_arquivo(nome_arquivo, dados):
with open(nome_arquivo, 'w') as arquivo:
json.dump(dados, arquivo)
def ler_arquivo(nome_arquivo):
with open(nome_arquivo, 'r') as arquivo:
return json.load(arquivo)
def main():
dados = {
'nome': 'Fulano',
'idade': 30,
'peso': 80.5
}
escrever_arquivo('dados.json', dados)
dados_lidos = ler_arquivo('dados.json')
print(dados_lidos)
# Para manipular um campo específico do arquivo, basta fazer:
dados_lidos['idade'] = 31
print(dados_lidos)
escrever_arquivo('dados.json', dados_lidos)
if __name__ == '__main__':
main()
Vamos avaliar o código anterior por partes:
-
import json: Importa a bibliotecajson. Ela é uma biblioteca built-in do Python que nos permite trabalhar com arquivos JSON. -
escrever_arquivo: Função para escrever os dados em um arquivo JSON. Ela recebe o nome do arquivo e os dados a serem escritos. O métododumpescreve os dados no arquivo. Importante Destacar: o métododumprecebe como parâmetro o objeto a ser escrito e o arquivo onde ele será escrito. Este objeto pode ser um dicionário, uma lista, um número, uma string, um booleano ou um nulo. -
ler_arquivo: Função para ler os dados de um arquivo JSON. Ela recebe o nome do arquivo e retorna os dados lidos. O métodoloadlê os dados do arquivo. Importante Destacar: o métodoloadrecebe como parâmetro o arquivo de onde os dados serão lidos. Ele retorna o objeto lido do arquivo.
Mas Murilão, e se for necessário manipular diversas entradas? É possível sim, o JSON é um formato de arquivo bastante flexível. Ele suporta objetos, arrays, strings, números, booleanos e nulos. Isso significa que você pode armazenar diversos tipos de dados em um arquivo JSON. Além disso, você pode armazenar objetos dentro de objetos, arrays dentro de objetos, objetos dentro de arrays, entre outras combinações.
Mas pessoal, está ficando complexo a manipulação de arquivos. Será que não existe uma forma mais interessante de armazenar os dados? Algo que facilite a leitura de um valor específico, como o que foi setado para uma configuração específica? Claro que existe! Podemos trabalhar com bancos de dados.
4.3. Bancos de Dados Relacionais
Uma das formas mais comuns de armazenar dados é utilizando bancos de dados. Os bancos de dados são sistemas que permitem armazenar, manipular e recuperar dados. Existem diversos tipos de bancos de dados, como por exemplo, os bancos de dados relacionais, os bancos de dados documentais, os bancos de dados de séries temporais, os bancos de dados de grafos, entre outros.
Os bancos de dados relacionais são um dos tipos mais comuns de bancos de dados. Eles são baseados no modelo relacional, que é um modelo de dados que organiza os dados em tabelas. Cada tabela é composta por linhas e colunas. As linhas representam os registros e as colunas representam os campos. Os bancos de dados relacionais são bastante utilizados em sistemas de informação, sistemas de gerenciamento de conteúdo, sistemas de gerenciamento de relacionamento com o cliente, entre outros.
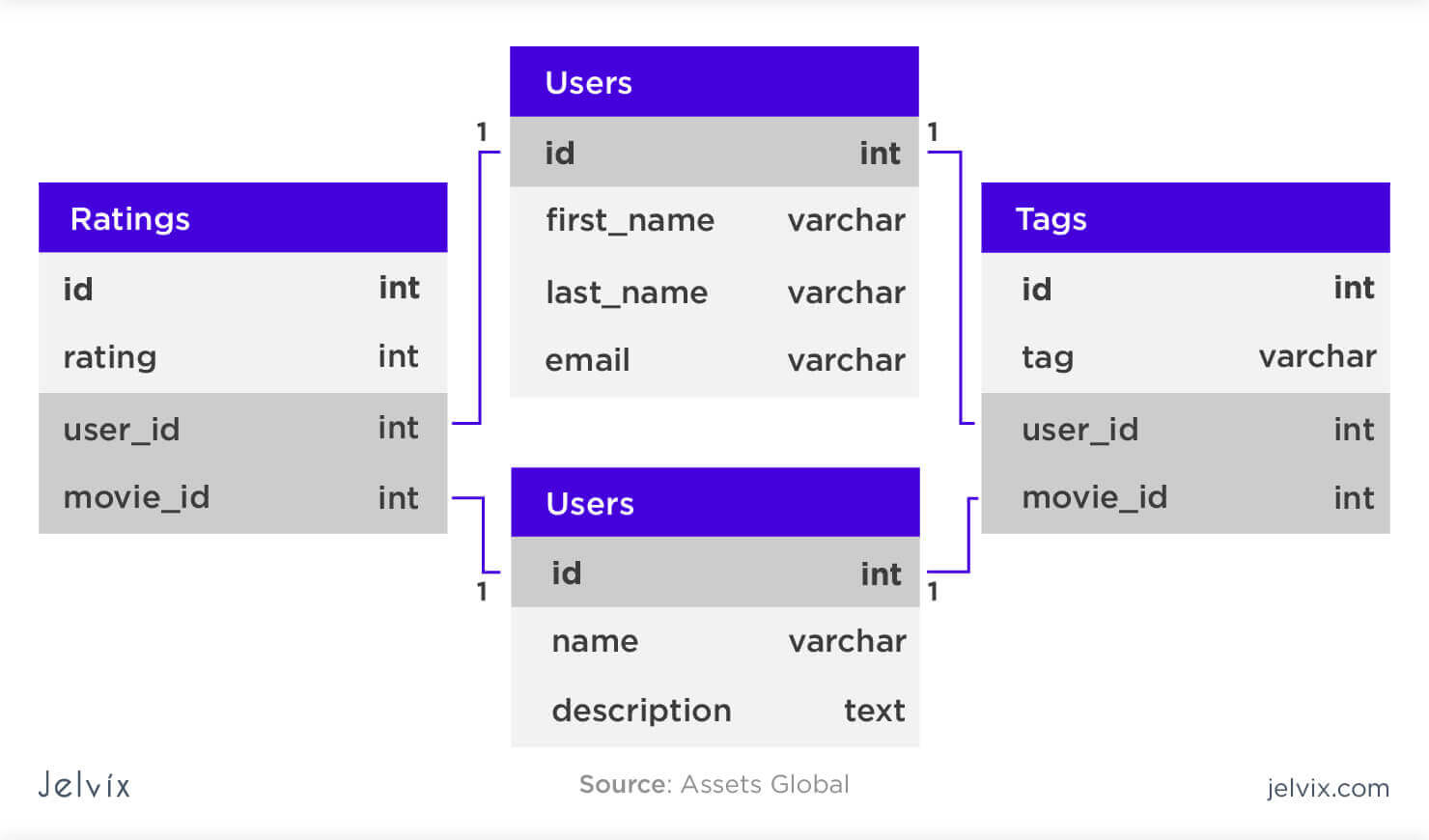
Cada linha de uma tabela é um registro. Cada coluna de uma tabela é um campo. Cada tabela tem um nome único. Cada campo tem um nome único. Cada campo tem um tipo de dado. Cada registro tem um valor para cada campo. Cada registro é único. Cada campo pode ser uma chave primária, que é um campo que identifica unicamente um registro. Cada campo pode ser uma chave estrangeira, que é um campo que referencia um registro de outra tabela.
Quando estamos trabalhando com bancos relacionais, precisamos definir o esquema do banco de dados. O esquema é a estrutura do banco de dados. Ele define as tabelas, os campos, os tipos de dados, as chaves primárias, as chaves estrangeiras, as restrições, entre outros. O esquema é definido utilizando uma linguagem de definição de dados, como por exemplo, o SQL (Structured Query Language).
Existem diversos tipos de software que permitem trabalhar com os bancos de dados relacionais. Eles são os responsáveis por garantir a integridade dos dados, a segurança dos dados, a recuperação dos dados, entre outros. Alguns exemplos de software de bancos de dados relacionais são o MySQL, o PostgreSQL, o SQLite, o Oracle, o SQL Server, entre outros.
Vamos trabalhar com o banco de dados relacional SQLite. O SQLite é um banco de dados relacional que é embutido na maioria dos sistemas operacionais. Ele é um banco de dados relacional que é bastante utilizado em sistemas embarcados, sistemas de desktop, sistemas móveis, entre outros. O SQLite é um banco de dados relacional que é bastante leve e que não requer um servidor. Ele é um banco de dados relacional que é bastante rápido e que suporta a maioria das funcionalidades do SQL. Para maiores informações, consulte a documentação oficial.
De forma build-in, o Python já possui uma biblioteca para trabalhar com o SQLite. Vamos trabalhar com o arquivo sqlite_v1.py. Para executar ele vamos rodar o comando: python3 src/sqlite_v1.py.
# sqlite_v1.py
import sqlite3
def criar_tabela(conexao):
cursor = conexao.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS pessoa (
id INTEGER PRIMARY KEY AUTOINCREMENT,
nome TEXT NOT NULL,
idade INTEGER NOT NULL
)
''')
conexao.commit()
def inserir_pessoa(conexao, nome, idade):
cursor = conexao.cursor()
cursor.execute('''
INSERT INTO pessoa (nome, idade) VALUES (?, ?)
''', (nome, idade))
conexao.commit()
def listar_pessoas(conexao):
cursor = conexao.cursor()
cursor.execute('''
SELECT id, nome, idade FROM pessoa
''')
for pessoa in cursor.fetchall():
print(pessoa)
def main():
conexao = sqlite3.connect('pessoas.db')
criar_tabela(conexao)
inserir_pessoa(conexao, 'Fulano', 30)
inserir_pessoa(conexao, 'Ciclano', 25)
listar_pessoas(conexao)
conexao.close()
if __name__ == '__main__':
main()
Vamos avaliar o código anterior por partes:
-
import sqlite3: Importa a bibliotecasqlite3. Ela é uma biblioteca built-in do Python que nos permite trabalhar com o SQLite. -
criar_tabela: Função para criar a tabela no banco de dados. Ela recebe a conexão com o banco de dados. O métodocursorcria um cursor para executar comandos SQL. O métodoexecuteexecuta o comando SQL para criar a tabela. Dentro do métodoexecute, utilizando os comandos SQL para criar a tabelapessoa, com os campos:id,nomeeidade. O métodocommitconfirma a transação. -
inserir_pessoa: Função para inserir uma pessoa na tabela do banco de dados. Ela recebe a conexão com o banco de dados, o nome e a idade da pessoa. O métodocursorcria um cursor para executar comandos SQL. O métodoexecuteexecuta o comando SQL para inserir a pessoa na tabela. Dentro do métodoexecute, utilizando os comandos SQL para inserir a pessoa na tabelapessoa. O métodocommitconfirma a transação. -
listar_pessoas: Função para listar as pessoas da tabela do banco de dados. Ela recebe a conexão com o banco de dados. O métodocursorcria um cursor para executar comandos SQL. O métodoexecuteexecuta o comando SQL para listar as pessoas da tabela. O métodofetchallretorna todas as linhas do resultado da consulta. O métodoprintimprime as pessoas.
Mas Murilão, e se for necessário manipular diversas entradas? É possível sim, o SQLite é um banco de dados relacional que suporta a maioria das funcionalidades do SQL. Isso significa que você pode criar tabelas, inserir registros, listar registros, atualizar registros, deletar registros, entre outras operações.
Podemos observar que o arquivo pessoas.db foi criado no mesmo diretório do arquivo que está sendo executado. Caso você queira criar o arquivo em outro diretório, você deve passar o caminho completo do arquivo. Por exemplo, se você quiser criar o arquivo pessoas.db no diretório dados, você pode passar o caminho completo do arquivo: dados/pessoas.db.
Este arquivo pode ser manipulado utilizando editores de banco de dados, como por exemplo, o DBeaver, o DB Browser for SQLite, entre outros.
Agora vamos trabalhar com o arquivo sqlite_v2.py. Para executar ele vamos rodar o comando: python3 src/sqlite_v2.py. Ele vai acessar o banco de dados faker.db que está no diretório src.
# sqlite_v2.py
import sqlite3
class Funcionario:
def __init__(self, nome, email, idade, salario):
self.nome = nome
self.idade = idade
self.salario = salario
self.email = email
def __str__(self):
return f'{self.nome} - {self.email} - {self.idade} - {self.salario}'
def ler_funcionario(conexao, id):
cursor = conexao.cursor()
cursor.execute('''
SELECT nome, email, idade, salario FROM funcionarios WHERE id = ?
''', (id))
pessoa = cursor.fetchone()
if pessoa:
print(pessoa)
return Funcionario(*pessoa)
else:
print('Pessoa não encontrada')
return None
def listar_funcionarios(conexao):
cursor = conexao.cursor()
cursor.execute('''
SELECT nome, email, idade, salario FROM funcionarios
''')
for pessoa in cursor.fetchall():
print(pessoa)
def main():
conexao = sqlite3.connect('faker.db')
listar_funcionarios(conexao)
conexao.close()
if __name__ == '__main__':
main()
A primeira grande diferença que podemos observar é que não estamos mais criando nosso banco, estamos acessando um banco que já foi criado. Além disso, estamos utilizando uma classe para representar os dados que estamos manipulando. Isso é uma prática bastante comum quando estamos trabalhando com bancos de dados.
Vamos avaliar o código anterior por partes:
-
class Funcionario: Classe para representar um funcionário. Ela possui um método__init__para inicializar os atributos da classe e um método__str__para representar a classe como uma string. -
ler_funcionario: Função para ler um funcionário do banco de dados. Ela recebe a conexão com o banco de dados e o id do funcionário. O métodocursorcria um cursor para executar comandos SQL. O métodoexecuteexecuta o comando SQL para ler o funcionário do banco de dados. O métodofetchoneretorna a primeira linha do resultado da consulta. O métodoprintimprime o funcionário. -
listar_funcionarios: Função para listar os funcionários do banco de dados. Ela recebe a conexão com o banco de dados. O métodocursorcria um cursor para executar comandos SQL. O métodoexecuteexecuta o comando SQL para listar os funcionários do banco de dados. O métodofetchallretorna todas as linhas do resultado da consulta. O métodoprintimprime os funcionários.
Mas Murilão, e se for necessário manipular diversas entradas? É possível sim, o SQLite é um banco de dados relacional que suporta a maioria das funcionalidades do SQL. Isso significa que você pode criar tabelas, inserir registros, listar registros, atualizar registros, deletar registros, entre outras operações.
Agora, será que existe uma forma mais interessante de armazenar os dados? Algo que facilite a leitura de um valor específico, como o que foi setado para uma configuração específica? Claro que existe! Podemos trabalhar com bancos de dados documentais.
4.4. Bancos de Dados Documentais
Bancos de dados documentais fazem parte da categoria de banco de dados chamada de NoSQL. NoSQL é um termo genérico que se refere a bancos de dados que não utilizam o modelo relacional. Os bancos de dados documentais são um dos tipos mais comuns de bancos de dados NoSQL. Eles são baseados no modelo de documento, que é um modelo de dados que organiza os dados em documentos. Cada documento é composto por campos e valores. Os bancos de dados documentais são bastante utilizados em sistemas de gerenciamento de conteúdo, sistemas de gerenciamento de relacionamento com o cliente, sistemas de gerenciamento de conteúdo, entre outros.
Para trabalharmos com os bancos documentais, vamos utilizar a biblioteca TinyDB. O TinyDB é um banco de dados documental que é bastante leve e que não requer um servidor. Ele é um banco de dados documental que é bastante rápido e que suporta a maioria das funcionalidades do SQL. Para maiores informações, consulte a documentação oficial.
Primeiro vamos instalar o TinyDB utilizando o pip. Para isso, vamos rodar o comando: pip3 install tinydb.
Agora vamos trabalhar com o arquivo tinydb_v1.py. Para executar ele vamos rodar o comando: python3 src/tinydb_v1.py.
# tinydb_v1.py
from tinydb import TinyDB, Query
def main():
db = TinyDB('usuarios.json')
User = Query()
db.insert({'name': 'John', 'age': 22})
user = db.search(User.name == 'John')
print(user)
if __name__ == '__main__':
main()
Vamos avaliar o código anterior por partes:
-
from tinydb import TinyDB, Query: Importa a classeTinyDBe a classeQueryda bibliotecaTinyDB. -
db = TinyDB('usuarios.json'): Cria um banco de dados documental chamadousuarios.json. -
User = Query(): Cria um objetoUserpara realizar consultas no banco de dados. -
db.insert({'name': 'John', 'age': 22}): Insere um documento no banco de dados. -
user = db.search(User.name == 'John'): Realiza uma consulta no banco de dados. -
print(user): Imprime o resultado da consulta.
Agora vamos criar um arquivo tinydb_v2.py. Para executar ele vamos rodar o comando: python3 src/tinydb_v2.py.
# tinydb_v2.py
from tinydb import TinyDB, Query
class Ponto:
def __init__(self, x, y, z, r):
self.x = x
self.y = y
self.z = z
self.r = r
def __str__(self):
return f'({self.x}, {self.y}, {self.z}) - {self.r}'
def inserir_ponto(db, ponto):
db.insert({'x': ponto.x, 'y': ponto.y, 'z': ponto.z, 'r': ponto.r})
def listar_pontos(db):
return db.all()
def main():
db = TinyDB('pontos.json')
buscador = Query()
inserir_ponto(db, Ponto(1, 2, 3, 4))
inserir_ponto(db, Ponto(5, 6, 7, 8))
pontos_inseridos = listar_pontos(db)
print(pontos_inseridos)
if __name__ == '__main__':
main()
Pessoal agora vamos utilizar o conteúdo para resolver o nosso problema do projeto. Gambatte! 🚀🚀
4.5 Um Pouco de Diversão
Pessoal vamos agora construir um software do tipo TO-DO List, mas utilizando o banco de dados TinyDB. Vamos trabalhar com o arquivo tinydb_v3.py. Para executar ele vamos rodar o comando: python3 src/tinydb_v3.py.
# tinydb_v3.py
# Construindo um CRUD de notas com o TinyDB
from tinydb import TinyDB, Query
from datetime import datetime
class Nota:
def __init__(self, titulo, texto):
self.titulo = titulo
self.texto = texto
self.data_modificacao = None
# Cria o registro da hora que a nota foi criada
self.data_criado = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
def __str__(self):
return f'{self.titulo} - {self.texto} - {self.data_criado} - {self.data_modificacao}'
# CRUD com as notas
def inserir_nota(db, nota):
db.insert({'titulo': nota.titulo, 'texto': nota.texto, 'data_criado': nota.data_criado, 'data_modificacao': nota.data_modificacao})
def listar_notas(db):
return db.all()
def buscar_nota(db, titulo):
buscador = Query()
return db.search(buscador.titulo == titulo)
def atualizar_nota(db, titulo, texto):
buscador = Query()
db.update({'texto': texto, 'data_modificacao': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}, buscador.titulo == titulo)
def deletar_nota(db, titulo):
buscador = Query()
db.remove(buscador.titulo == titulo)
# Agora lógica prinicipal do programa
def main():
db = TinyDB('notas.json')
continuar = True
while continuar:
print('1. Inserir nota')
print('2. Listar notas')
print('3. Buscar nota')
print('4. Atualizar nota')
print('5. Deletar nota')
print('6. Sair')
opcao = int(input('Escolha uma opção: '))
if opcao == 1:
titulo = input('Digite o título da nota: ')
texto = input('Digite o texto da nota: ')
inserir_nota(db, Nota(titulo, texto))
elif opcao == 2:
notas = listar_notas(db)
for nota in notas:
print(f'{nota["titulo"]} - {nota["texto"]} - {nota["data_criado"]} - {nota["data_modificacao"]}')
elif opcao == 3:
titulo = input('Digite o título da nota: ')
nota = buscar_nota(db, titulo)
print(nota)
elif opcao == 4:
titulo = input('Digite o título da nota: ')
texto = input('Digite o texto da nota: ')
atualizar_nota(db, titulo, texto)
elif opcao == 5:
titulo = input('Digite o título da nota: ')
deletar_nota(db, titulo)
elif opcao == 6:
continuar = False
else:
print('Opção inválida')
if __name__ == '__main__':
main()
Pessoal aqui temos muitas coisas acontecendo. A primeira delas que vale a pena mencionar é que este software PODE e DEVE ser melhorado. No entanto, ele já é um bom ponto de partida para entendermos como podemos utilizar o TinyDB para construir um software de TO-DO List.
Feito está observação, vamos compreender o que este software está realizando e como ele faz isso analisando alguns dos seus blocos de código primeiro. O objetivo de um software de TO-DO List é permitir que o usuário possa criar, listar, buscar, atualizar e deletar notas. Isso é realizado exibindo um menu para o usuário para que ele possa interagir com nossa aplicação.
Pessoal discutimos que o software pode e deve ser melhorado. Uma das formas de melhorar este software é melhorar a CLI. A CLI é a interface de linha de comando. Ela é a forma como o usuário interage com o software. Uma forma de melhorar a CLI é utilizando uma biblioteca para construir interfaces de linha de comando, como as que estudamos ainda está semana. Não deixem de fazer essa modificação.
Pode ser dificil de perceber no início, mas muito do que fazemos com o desenvolvimento de software vem do volume que praticamos para desenvolver! Gambatte!
Legal, agora que sabemos o objetivo do nosso sistema, vamos começar a analisar como ele alcança eles! Primeiro, todas as nossas notas ficam armazenadas em um arquivo chamado notas.json. Este arquivo é criado quando o software é executado pela primeira vez. Se o arquivo já existe, ele é utilizado para receber as novas notas e atualização das antigas.
Quando utilizamos um arquivo JSON para armazenar nossas informações, todas elas estão abertas e podem ser lidas sem maiores problemas. Tomar muito cuidado com o conteúdo dessas informações para evitar que informações sensíveis fiquem expostas.
Agora vamos analisar o código fonte do arquivo tinydb_v3.py. Primeiro importamos os módulos TinyDB e Query para manipular nossos registros. O módulo datetime por sua vez é utilizado para armazenar informações de datas. Vamos avaliar a classe Nota.
class Nota:
def __init__(self, titulo, texto):
self.titulo = titulo
self.texto = texto
self.data_modificacao = None
# Cria o registro da hora que a nota foi criada
self.data_criado = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
def __str__(self):
return f'{self.titulo} - {self.texto} - {self.data_criado} - {self.data_modificacao}'
A classe Nota serve para representar as notas que serão armazenadas no banco de dados. Ela possui um método __init__ para inicializar os atributos da classe e um método __str__ para representar a classe como uma string. O método __init__ recebe o título e o texto da nota. Ele inicializa os atributos titulo, texto, data_modificacao e data_criado. O atributo data_modificacao é inicializado como None. O atributo data_criado é inicializado com a data e hora atual. Repare que a data de inicialização não fica por conta do usuário, é uma forma de garantir o funcionamento do sistema. O método __str__ retorna uma string com o título, o texto, a data de criação e a data de modificação da nota.
Agora vamos analisar as funções que realizam as operações de CRUD.
# Restante do código omitido
# CRUD com as notas
def inserir_nota(db, nota):
db.insert({'titulo': nota.titulo, 'texto': nota.texto, 'data_criado': nota.data_criado, 'data_modificacao': nota.data_modificacao})
def listar_notas(db):
return db.all()
def buscar_nota(db, titulo):
buscador = Query()
return db.search(buscador.titulo == titulo)
def atualizar_nota(db, titulo, texto):
buscador = Query()
db.update({'texto': texto, 'data_modificacao': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}, buscador.titulo == titulo)
def deletar_nota(db, titulo):
buscador = Query()
db.remove(buscador.titulo == titulo)
Analisando os métodos individualmente:
-
inserir_nota: Função para inserir uma nota no banco de dados. Ela recebe o banco de dados e a nota a ser inserida. O métodoinsertinsere a nota no banco de dados. Repare que os campos da nota são enviados como um dicionário. -
listar_notas: Função para listar as notas do banco de dados. Ela recebe o banco de dados. O métodoallretorna todas as notas do banco de dados. Volta uma lista de dicionários. -
buscar_nota: Função para buscar uma nota no banco de dados. Ela recebe o banco de dados e o título da nota. O métodosearchretorna a nota do banco de dados que possui o título informado. -
atualizar_nota: Função para atualizar uma nota no banco de dados. Ela recebe o banco de dados, o título da nota e o texto da nota. O métodoupdateatualiza a nota no banco de dados. Repare que a data de modificação é atualizada para a data e hora atual. -
deletar_nota: Função para deletar uma nota no banco de dados. Ela recebe o banco de dados e o título da nota. O métodoremovedeleta a nota do banco de dados.
Se observarmos os métodos implementados, eles são bastante simples e diretos. Eles realizam as operações de CRUD de forma bastante eficiente. No entanto, é importante destacar que todos os métodos estão utilizando dicionários, que é o formato esperado pelo TinyDB. Isso significa que o TinyDB é bastante flexível e suporta a maioria das operações de CRUD.
Agora vamos modificar esse CRUD para que ele trabalhe com representações de objetos da classe Nota. Vamos alterar o programa.
# tinydb_v3.py
# Construindo um CRUD de notas com o TinyDB
from tinydb import TinyDB, Query
from datetime import datetime
class Nota:
def __init__(self, titulo = None, texto = None):
self.titulo = titulo
self.texto = texto
self.data_modificacao = None
# Cria o registro da hora que a nota foi criada
self.data_criado = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
def __str__(self):
return f'{self.titulo} - {self.texto} - {self.data_criado} - {self.data_modificacao}'
# Funções auxiliares
def nota_to_dict(self):
return {'titulo': self.titulo, 'texto': self.texto, 'data_criado': self.data_criado, 'data_modificacao': self.data_modificacao}
@staticmethod
def dict_to_nota( nota_dict):
nota = Nota()
nota.titulo = nota_dict['titulo']
nota.texto = nota_dict['texto']
nota.data_criado = nota_dict['data_criado']
nota.data_modificacao = nota_dict['data_modificacao']
return nota
@staticmethod
def db_to_nota(nota_db):
nota = Nota(nota_db['titulo'], nota_db['texto'])
nota.data_criado = nota_db['data_criado']
nota.data_modificacao = nota_db['data_modificacao']
return nota
# CRUD com as notas
def inserir_nota(db, nota):
db.insert(nota.nota_to_dict())
def listar_notas(db):
return [Nota.db_to_nota(nota) for nota in db.all()]
def buscar_nota(db, titulo):
buscador = Query()
nota = db.search(buscador.titulo == titulo)
if nota:
return Nota.dict_to_nota(nota[0])
else:
return None
def atualizar_nota(db, titulo, texto):
buscador = Query()
db.update({'texto': texto, 'data_modificacao': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}, buscador.titulo == titulo)
def deletar_nota(db, titulo):
buscador = Query()
db.remove(buscador.titulo == titulo)
# Agora lógica prinicipal do programa
def main():
db = TinyDB('notas.json')
continuar = True
while continuar:
print('1. Inserir nota')
print('2. Listar notas')
print('3. Buscar nota')
print('4. Atualizar nota')
print('5. Deletar nota')
print('6. Sair')
opcao = int(input('Escolha uma opção: '))
if opcao == 1:
titulo = input('Digite o título da nota: ')
texto = input('Digite o texto da nota: ')
inserir_nota(db, Nota(titulo, texto))
elif opcao == 2:
notas = listar_notas(db)
for nota in notas:
print(nota)
elif opcao == 3:
titulo = input('Digite o título da nota: ')
nota = buscar_nota(db, titulo)
print(nota)
elif opcao == 4:
titulo = input('Digite o título da nota: ')
texto = input('Digite o texto da nota: ')
atualizar_nota(db, titulo, texto)
elif opcao == 5:
titulo = input('Digite o título da nota: ')
deletar_nota(db, titulo)
elif opcao == 6:
continuar = False
else:
print('Opção inválida')
if __name__ == '__main__':
main()
Vamos observar as modificações realizadas no código:
-
Classe
Nota: Foram adicionados os métodosnota_to_dict,dict_to_notaedb_to_nota. O métodonota_to_dictretorna um dicionário com os atributos da nota. O métododict_to_notarecebe um dicionário e retorna uma nota. O métododb_to_notarecebe um dicionário e retorna uma nota. Reparar que os métodosdict_to_notaedb_to_notasão métodos estáticos. Isso significa que eles podem ser chamados sem a necessidade de instanciar um objeto da classeNota. -
Função
inserir_nota: Foi modificada para receber um objeto da classeNota. O métodoinsertrecebe um dicionário com os atributos da nota. -
Função
listar_notas: Foi modificada para retornar uma lista de objetos da classeNota. O métodoallretorna uma lista de dicionários. O métodolistar_notasretorna uma lista de objetos da classeNota. -
Função
buscar_nota: Foi modificada para retornar um objeto da classeNota. O métodosearchretorna uma lista de dicionários. O métodobuscar_notaretorna um objeto da classeNota.
Pessoal, o que acharam das modificações realizadas? Elas tornaram o código mais legível e mais fácil de ser mantido. Além disso, elas tornaram o código mais flexível e mais reutilizável. Isso significa que as modificações realizadas tornaram o código mais eficiente e mais eficaz.
Pessoal avaliem o software desenvolvido até aqui. Verifiquem se tem algum ponto que vocês ficaram com dúvidas ou que gostariam de melhorar. Isso é muito importante para o desenvolvimento de software. A prática leva a perfeição. Gambatte!
