Modelos de Classificação
Modelos de classificação são um tipo de modelo de machine learning supervisionado que têm como objetivo categorizar dados em classes ou categorias predefinidas. Esses modelos aprendem a partir de um conjunto de dados rotulado, onde cada exemplo é associado a uma classe específica, e depois utilizam esse conhecimento para prever a classe de novos dados. A classificação é amplamente utilizada em diversas aplicações, como reconhecimento de imagens, detecção de spam, diagnóstico médico, e muitas outras.
-
Regressão Logística:
- Embora o nome sugira uma relação com regressão, a regressão logística é usada para classificação binária, onde o objetivo é prever uma das duas classes possíveis (por exemplo, "sim" ou "não", "spam" ou "não spam"). O modelo estima a probabilidade de um dado exemplo pertencer a uma classe usando uma função logística, e a decisão final é baseada em um limiar predefinido.
-
Árvores de Decisão:
- Este modelo classifica dados dividindo-os em subconjuntos baseados em condições nas features. Uma árvore de decisão constrói uma estrutura em forma de árvore, onde cada nó representa uma decisão sobre uma feature, e cada folha representa uma classe. Árvores de decisão são intuitivas e fáceis de interpretar, embora possam se tornar complexas e propensas ao overfitting com dados ruidosos.
-
Máquinas de Vetores de Suporte (SVM):
- SVMs são modelos de classificação que procuram encontrar a hiperplano que melhor separa as classes em um espaço de alta dimensionalidade. O objetivo é maximizar a margem entre as classes, garantindo que os exemplos de diferentes classes estejam o mais distante possível do hiperplano de separação. SVMs são eficazes em casos de alta dimensionalidade e são robustos contra overfitting.
-
k-Nearest Neighbors (k-NN):
- O k-NN é um algoritmo de classificação simples e intuitivo que classifica um dado exemplo com base na classe da maioria dos seus k vizinhos mais próximos no espaço das features. Este modelo é não-paramétrico e bastante útil quando os dados têm uma estrutura clara e bem definida, embora possa ser computacionalmente intensivo em grandes conjuntos de dados.
-
Redes Neurais:
- As redes neurais artificiais são modelos complexos inspirados no cérebro humano. Elas consistem em várias camadas de nós (neurônios), onde cada camada aprende diferentes níveis de abstração dos dados. Redes neurais são altamente eficazes em tarefas complexas de classificação, especialmente em reconhecimento de imagem, voz e processamento de linguagem natural.
-
Naive Bayes:
- Este é um modelo probabilístico baseado no teorema de Bayes, que assume que as features são independentes entre si, uma suposição que raramente é verdadeira, mas que torna o modelo computacionalmente eficiente. Naive Bayes é especialmente útil em problemas de classificação de texto, como filtragem de spam, onde essa suposição de independência condicional é razoável.
Princípais Métricas de Avaliação
Para verificar as métricas de availação de modelos de classificação, vamos utilizar uma matriz de confusão. A matriz de confusão é uma tabela que mostra as frequências de classificação para cada classe do modelo. Ela é usada para avaliar o desempenho de um modelo de classificação em um conjunto de dados de teste para os quais os valores verdadeiros são conhecidos.
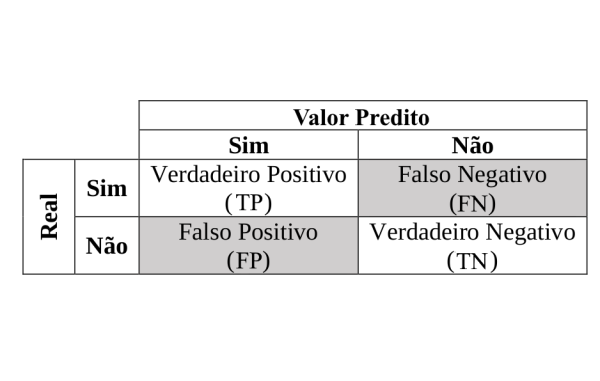
Ela divide as predições em quatro categorias:
- True Positives (TP): Previsões corretas da classe positiva.
- True Negatives (TN): Previsões corretas da classe negativa.
- False Positives (FP): Previsões incorretas onde a classe negativa foi prevista como positiva (também chamado de erro do Tipo I).
- False Negatives (FN): Previsões incorretas onde a classe positiva foi prevista como negativa (também chamado de erro do Tipo II).
1. Acurácia
-
A acurácia mede a proporção total de predições corretas (tanto positivas quanto negativas) em relação ao número total de exemplos. É calculada como:
-
Limitações: A acurácia pode ser enganosa em problemas de classificação com classes desbalanceadas, onde uma classe é muito mais frequente que a outra. Por exemplo, em um problema onde 95% dos exemplos pertencem à classe negativa, um modelo que prevê negativamente para todos os exemplos teria 95% de acurácia, mas não seria útil.
2. Precisão (Precision)
-
A precisão mede a proporção de predições positivas corretas em relação ao total de predições positivas feitas pelo modelo:
-
Importância: Alta precisão é importante quando o custo de um falso positivo é alto. Por exemplo, na detecção de spam, você não quer classificar e-mails importantes como spam.
3. Recall (ou Sensibilidade)
-
O recall mede a proporção de verdadeiros positivos que foram corretamente identificados pelo modelo em relação ao total de exemplos positivos reais:
-
Importância: O recall é crucial em situações onde perder um positivo verdadeiro é mais caro, como em diagnósticos médicos, onde falhar em detectar uma doença é mais prejudicial.
4. F1-Score
-
O F1-Score é a média harmônica entre precisão e recall, e é uma métrica útil quando há um trade-off entre esses dois aspectos:
-
Importância: O F1-Score é particularmente útil em situações de classes desbalanceadas, onde você deseja um equilíbrio entre precisão e recall.
5. Área sob a Curva ROC (AUC-ROC)
-
A curva ROC (Receiver Operating Characteristic) plota a taxa de verdadeiros positivos (TPR ou Sensibilidade) contra a taxa de falsos positivos (FPR) em diferentes limiares de decisão. A área sob a curva ROC (AUC-ROC) é uma métrica que resume a capacidade do modelo de discriminar entre as classes:
-
Importância: AUC-ROC é útil porque é independente do limiar de decisão, e uma AUC de 0,5 indica um modelo que não é melhor do que a chance, enquanto uma AUC de 1,0 indica um modelo perfeito.
6. Curva Precision-Recall (PR)
- A curva Precision-Recall é especialmente útil para problemas de classificação com classes desbalanceadas. Ela plota a precisão contra o recall em diferentes limiares de decisão. Em problemas onde a classe positiva é muito menos comum, a curva PR pode ser mais informativa que a curva ROC.
- AUC-PR: Semelhante ao AUC-ROC, a área sob a curva Precision-Recall (AUC-PR) é usada para medir a qualidade do modelo em problemas com classes desbalanceadas.
7. Cross-Validation
- A validação cruzada é uma técnica usada para avaliar o desempenho de um modelo de classificação de forma robusta. O conjunto de dados é dividido em vários subconjuntos (ou folds), e o modelo é treinado em alguns desses subconjuntos enquanto é testado nos outros. Esse processo é repetido várias vezes, e as métricas de desempenho são calculadas para cada iteração e depois são agregadas para obter uma estimativa geral.
- Importância: A validação cruzada ajuda a garantir que o modelo não esteja superajustado ao conjunto de treinamento e fornece uma estimativa mais confiável do desempenho do modelo em dados não vistos.
8. Matriz de Confusão Normalizada
- Em alguns casos, as métricas simples da matriz de confusão podem ser difíceis de interpretar, especialmente em problemas de classes desbalanceadas. A matriz de confusão normalizada divide cada valor pelo total de exemplos verdadeiros para cada classe, fornecendo uma visão proporcional de como o modelo está se comportando em relação a cada classe.
Escolhendo a Métrica Certa:
A escolha da métrica de avaliação depende muito do contexto do problema e do que é mais importante para o negócio ou aplicação. Por exemplo:
- Em um sistema de diagnóstico médico, recall (sensibilidade) pode ser priorizado para minimizar o número de casos de doença não detectados.
- Em sistemas de recomendação, precisão pode ser mais importante para garantir que as recomendações feitas sejam altamente relevantes.
Cada métrica traz uma perspectiva diferente sobre o desempenho do modelo, e frequentemente várias métricas são usadas em conjunto para obter uma visão mais completa.
Exemplos de Implementação
Exemplos de como escolher as métricas de avaliação para diferentes tipos de problemas de classificação:
1. Detecção de Fraude em Transações Financeiras
-
Problema: Identificar transações fraudulentas em tempo real.
-
Características do Problema: Este é um problema de classes desbalanceadas, onde a maioria das transações são legítimas e apenas uma pequena fração é fraudulenta.
-
Métricas Recomendadas:
- Recall: Utilizado quando o objetivo é minimizar os falsos negativos, ou seja, transações fraudulentas que não são identificadas como tais. Se uma transação fraudulenta não for detectada, o prejuízo pode ser significativo.
- Precision: Também importante para minimizar os falsos positivos, evitando que transações legítimas sejam marcadas erroneamente como fraudulentas, o que pode causar transtornos aos clientes.
- F1-Score: Uma métrica que equilibra precisão e recall, útil quando é necessário um bom desempenho em ambos os aspectos.
- AUC-ROC: Pode ser usada para avaliar a capacidade geral do modelo de distinguir entre transações fraudulentas e legítimas, independentemente do limiar de decisão.
-
Exemplo de Uso: Um banco utiliza um modelo de machine learning para analisar todas as transações em tempo real e classificar cada uma como fraudulenta ou legítima. Ao monitorar o F1-Score, o banco consegue ajustar o modelo para equilibrar a detecção de fraudes com a experiência do cliente, garantindo que transações legítimas não sejam bloqueadas injustamente.
2. Diagnóstico Médico de Doenças
-
Problema: Prever se um paciente tem uma doença específica com base em exames médicos.
-
Características do Problema: O erro de não identificar uma doença (falso negativo) pode ter consequências graves, como atrasos no tratamento.
-
Métricas Recomendadas:
- Recall: É a métrica mais importante, pois um alto recall garante que a maioria dos pacientes com a doença sejam corretamente identificados, minimizando os falsos negativos.
- Precision: É menos prioritária do que o recall, mas ainda importante para garantir que os pacientes diagnosticados como doentes realmente tenham a doença, evitando ansiedade ou tratamentos desnecessários.
- F1-Score: Pode ser usado para encontrar um equilíbrio adequado entre recall e precisão, especialmente se o tratamento de falsos positivos também tiver um custo significativo.
- AUC-ROC: Para avaliar a eficácia geral do modelo na discriminação entre pacientes doentes e não doentes.
-
Exemplo de Uso: Um hospital implementa um sistema de apoio à decisão médica que utiliza recall como a métrica principal. O sistema alerta os médicos para a possibilidade de doenças graves em pacientes com base nos resultados de exames. O hospital escolhe um modelo com alto recall, garantindo que a maioria dos casos suspeitos seja avaliada mais profundamente.
3. Classificação de E-mails como Spam
-
Problema: Identificar e-mails indesejados (spam) e separá-los dos e-mails legítimos (ham).
-
Características do Problema: Marcar um e-mail legítimo como spam (falso positivo) pode fazer com que o usuário perca mensagens importantes.
-
Métricas Recomendadas:
- Precision: Aqui o objetivo é minimizar os falsos positivos, ou seja, garantir que os e-mails legítimos não sejam classificados erroneamente como spam.
- Recall: Também importante, mas menos crítico que a precisão, porque um e-mail de spam não detectado é geralmente menos prejudicial do que um e-mail legítimo perdido.
- F1-Score: Pode ser usado se for necessário equilibrar precisão e recall, especialmente se a sensibilidade do filtro de spam precisar ser ajustada.
-
Exemplo de Uso: Um serviço de e-mail usa um modelo de classificação para filtrar spam. Eles monitoram a precisão do modelo para garantir que os e-mails importantes não sejam movidos para a pasta de spam. O serviço ajusta o modelo periodicamente para maximizar a precisão, mantendo o recall em um nível aceitável.
4. Sistema de Recomendação de Produtos
-
Problema: Sugerir produtos relevantes para os usuários com base em seu histórico de compras e comportamento de navegação.
-
Características do Problema: A experiência do usuário é crítica, e recomendações irrelevantes podem reduzir o engajamento.
-
Métricas Recomendadas:
- Precision: É a métrica mais importante, pois você quer garantir que as recomendações feitas sejam altamente relevantes e tenham uma alta probabilidade de conversão.
- Recall: Menos prioritário que a precisão, mas ainda relevante para garantir que o modelo sugira uma variedade de produtos de interesse do usuário.
- AUC-ROC ou AUC-PR: Pode ser útil para avaliar a eficácia geral do modelo em prever a probabilidade de um produto ser relevante.
-
Exemplo de Uso: Uma plataforma de e-commerce implementa um sistema de recomendação que se concentra na precisão. Eles ajustam o modelo para garantir que os produtos sugeridos tenham alta probabilidade de compra pelo usuário, maximizando as taxas de conversão e melhorando a experiência do usuário.
5. Classificação de Sentimentos em Redes Sociais
-
Problema: Classificar postagens de usuários como positivas, negativas ou neutras.
-
Características do Problema: A precisão da detecção de sentimentos é importante para analisar o feedback dos clientes.
-
Métricas Recomendadas:
- F1-Score: Útil quando o equilíbrio entre precisão e recall é necessário, especialmente se os sentimentos positivos e negativos forem igualmente importantes.
- Acurácia: Pode ser usada quando as classes estão balanceadas e o objetivo é uma visão geral da performance.
- Recall para cada classe: Pode ser relevante se a empresa está mais preocupada com a detecção de sentimentos específicos, como a identificação de feedbacks negativos para resolução de problemas.
-
Exemplo de Uso: Uma empresa monitora as postagens sobre sua marca nas redes sociais. Eles usam o F1-Score como a métrica principal para garantir que o modelo capture bem tanto o feedback positivo quanto o negativo, ajudando na gestão da reputação online.
6. Reconhecimento de Imagem
-
Problema: Identificar objetos ou categorias em imagens (por exemplo, identificar espécies de animais em fotos).
-
Características do Problema: O modelo deve ser preciso, mas também sensível o suficiente para detectar todas as instâncias de um objeto.
-
Métricas Recomendadas:
- Precision: Importante para evitar a classificação incorreta de objetos semelhantes.
- Recall: Também importante para garantir que todas as instâncias do objeto sejam identificadas, especialmente em tarefas críticas, como diagnósticos médicos por imagem.
- AUC-ROC: Pode ser usado para avaliar a capacidade do modelo de distinguir entre diferentes categorias ou classes de objetos.
-
Exemplo de Uso: Uma aplicação de monitoramento da vida selvagem usa reconhecimento de imagem para identificar espécies de animais. Eles escolhem um modelo que maximiza tanto a precisão quanto o recall, garantindo que todas as espécies sejam identificadas corretamente sem confundir espécies semelhantes.
A combinação certa de métricas pode fornecer uma visão abrangente do desempenho do modelo, permitindo ajustes finos para otimizar os resultados.